
Devlog #01: Emulador NES, Github e build simples com Github Actions

Este artigo é uma continuação da série “Emulador NES” que vai te mostrar e implementar contigo um emulador NES totalmente funcional utilizando a linguagem C e a biblioteca Raylib. Clique aqui para ler o artigo anterior.
O resultado do trabalho deste artigo você consegue conferir no primeiro Pull Request do projeto: https://github.com/codamos-com-br/qmario/pull/1.
No artigo anterior
Nós já tivemos uma visão geral da arquitetura do NES e quais componentes vamos precisar emular.
Agora é hora de botar a mão na massa! Hoje nós vamos criar uma suíte de integração contínua que vai nos permitir compilar e rodar testes, para que possamos detectar com facilidade se algum erro aconteceu e quando.
Vídeo de apoio
Tem muita coisa acontecendo ao mesmo tempo neste artigo e, apesar de eu ter tentado deixar ele organizadinho, algumas coisas ainda podem ter ficado confusas.
Eu gravei um vídeo mostrando a implementação passo a passo de tudo o que vamos falar aqui, talvez assim fique um pouco mais fácil de acompanhar o processo que, como um todo, é bem complicadinho.
Criar e clonar um novo repositório no Github
O meu primeiro passo aqui é criar um repositório no Github. Isso vai me ajudar a guardar os arquivos e versionar tudo, mas também vai permitir que você dê uma olhada no código e envie algumas correções, faça perguntas pontuais e por aí vai…
Na página do seu perfil ou organização, clique em “Repositories” e encontre o botão “New repository”:

Daí basta colocar as informações básicas sobre o projeto. Eu vou chamar este emulador de “qmario” (🤭) e você pode acessar a partir deste link aqui: https://github.com/codamos-com-br/qmario.
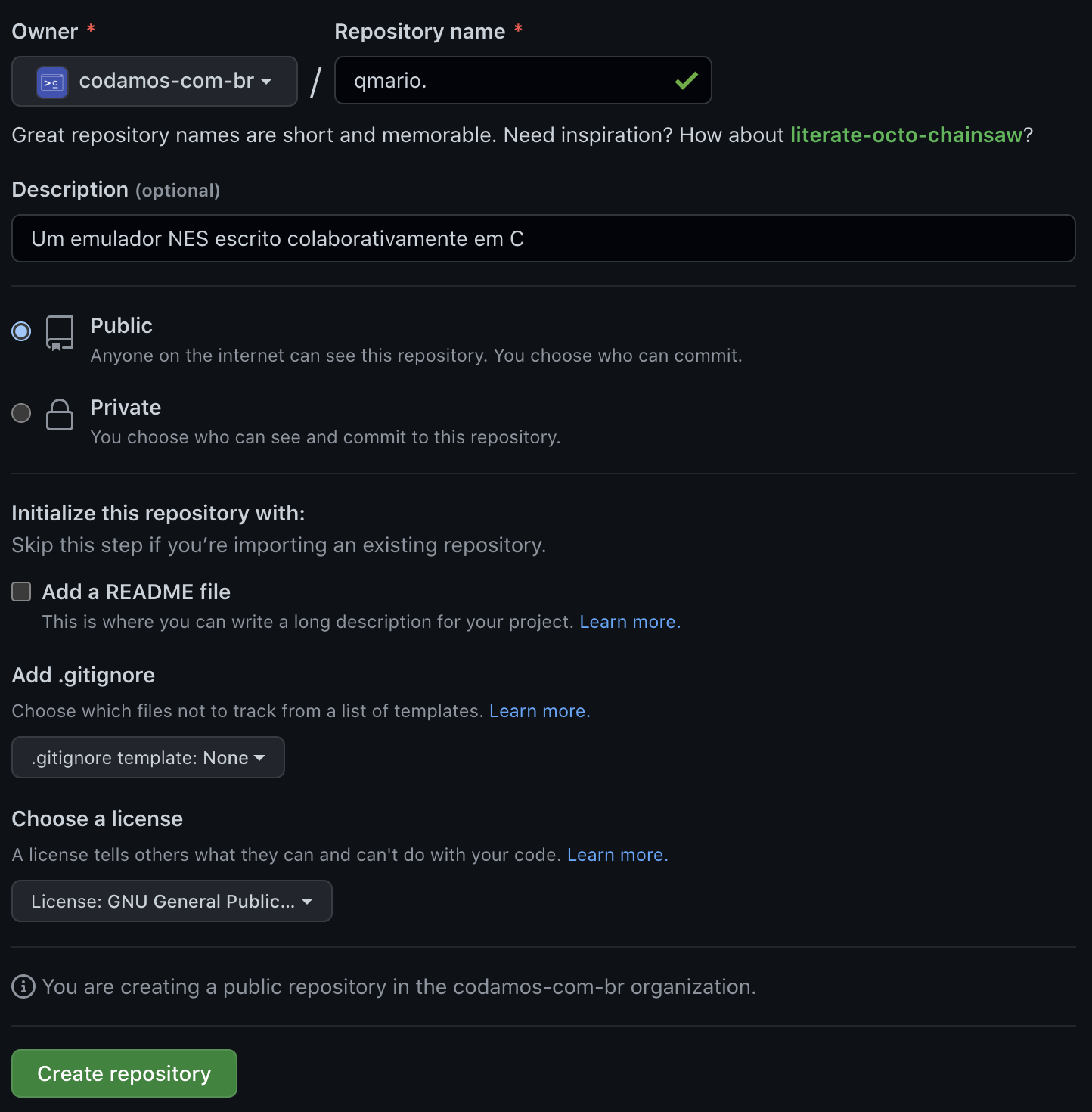
Agora basta visitar a página principal do repositório, clicar no botão primário “Code” para então escolher a aba “SSH” e copiar a URL que o Github nos oferece na caixa de texto.
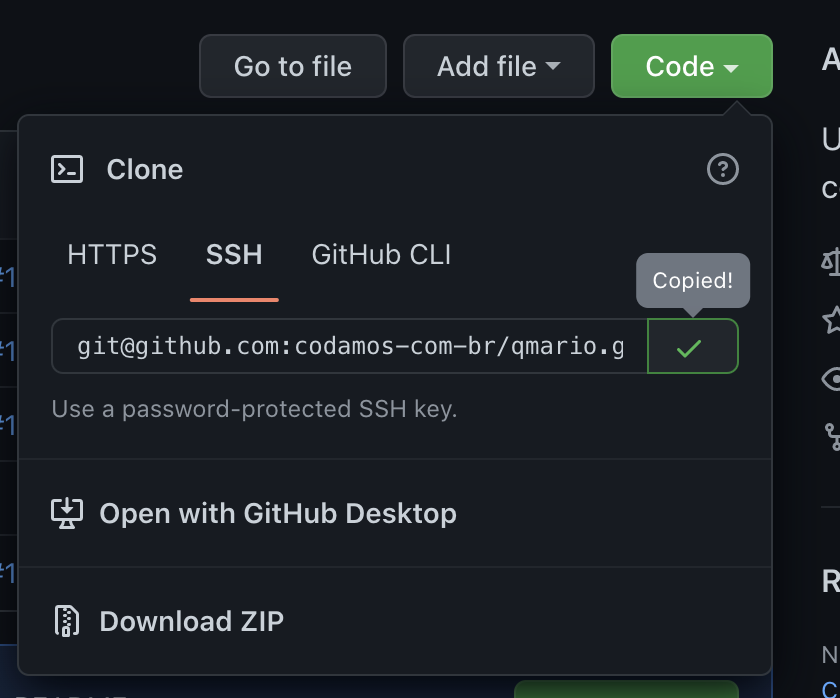
Com esta URL eu posso clonar o repositório pro meu computador utilizando o seguinte comando:
$ git clone [email protected]:codamos-com-br/qmario.git
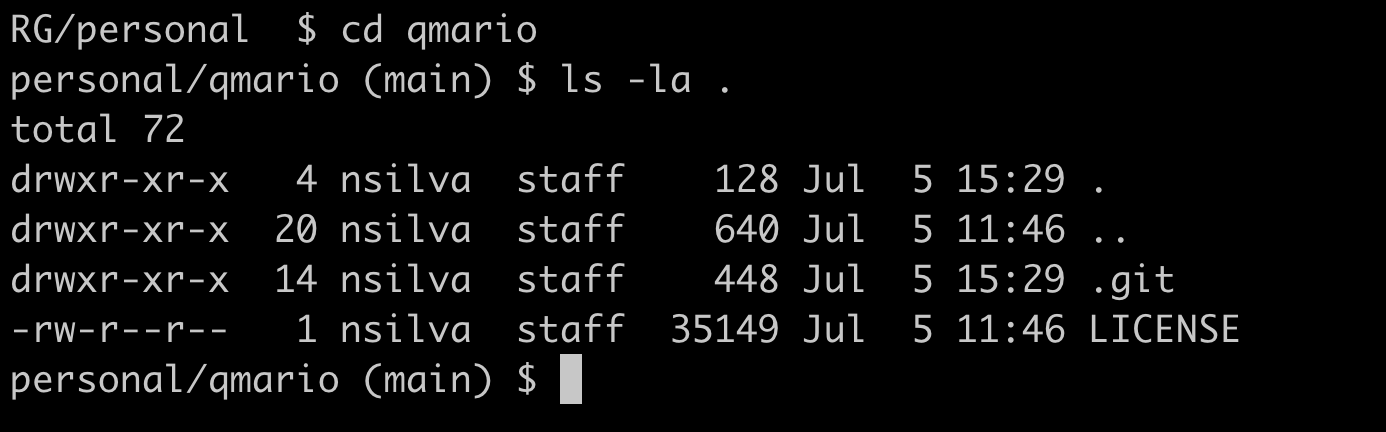
Ao entrar na pasta que acabei de clonar, posso listar todos os arquivos. Como é um repositório novo, apenas .git e LICENSE deverão existir:
Caso não saiba como mexer com Github ou subir arquivos lá, o João escreveu um post incrível com um passo a passo muito bem feito sobre como subir arquivos para um projeto no Github.
Integração contínua com Github Actions: qualidade garantida desde o início
O primeiro passo essencial ao criar qualquer projeto, é configurar uma suíte de integração contínua. Desta forma a gente garante desde o dia 1 do projeto que está pronto para se construído e entregue a qualquer computador.
No Github podemos utilizar workflows do Github Actions para integração contínua.
Antes de tudo, vamos criar um branch novo para receber nossas alterações. Vou chamar este branch de ci_workflow.
$ git checkout -b ci_workflow

Agora podemos começar a montar a nossa pipeline de integração contínua. Vamos criar um arquivo chamado .github/workflows/ci.yaml:
$ mkdir -p .github/workflows
$ vim .github/workflows/ci.yaml

Para criar e editar o arquivo eu utilizei o editor VIM, mas você pode usar qualquer outro editor de sua preferência. Para saber sobre VIM, dê uma olhada neste artigo que escrevi sobre como começar com VIM.
Agora vamos dar o seguinte conteúdo ao arquivo ci.yaml:
# .github/workflows/ci.yaml
name: CI
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Fazer build e rodar
run: echo 'Olá github actions'
Note que, de acordo com o conteúdo acima, a pipeline build vai rodar sempre que fizermos um push ou abrirmos um pull_request que afete o branch main.
Vamos então fazer um commit e enviar nossas alterações:
$ git add .github/.
$ git commit -m "ci: adiciona workflow simples"
$ git push origin ci_workflow
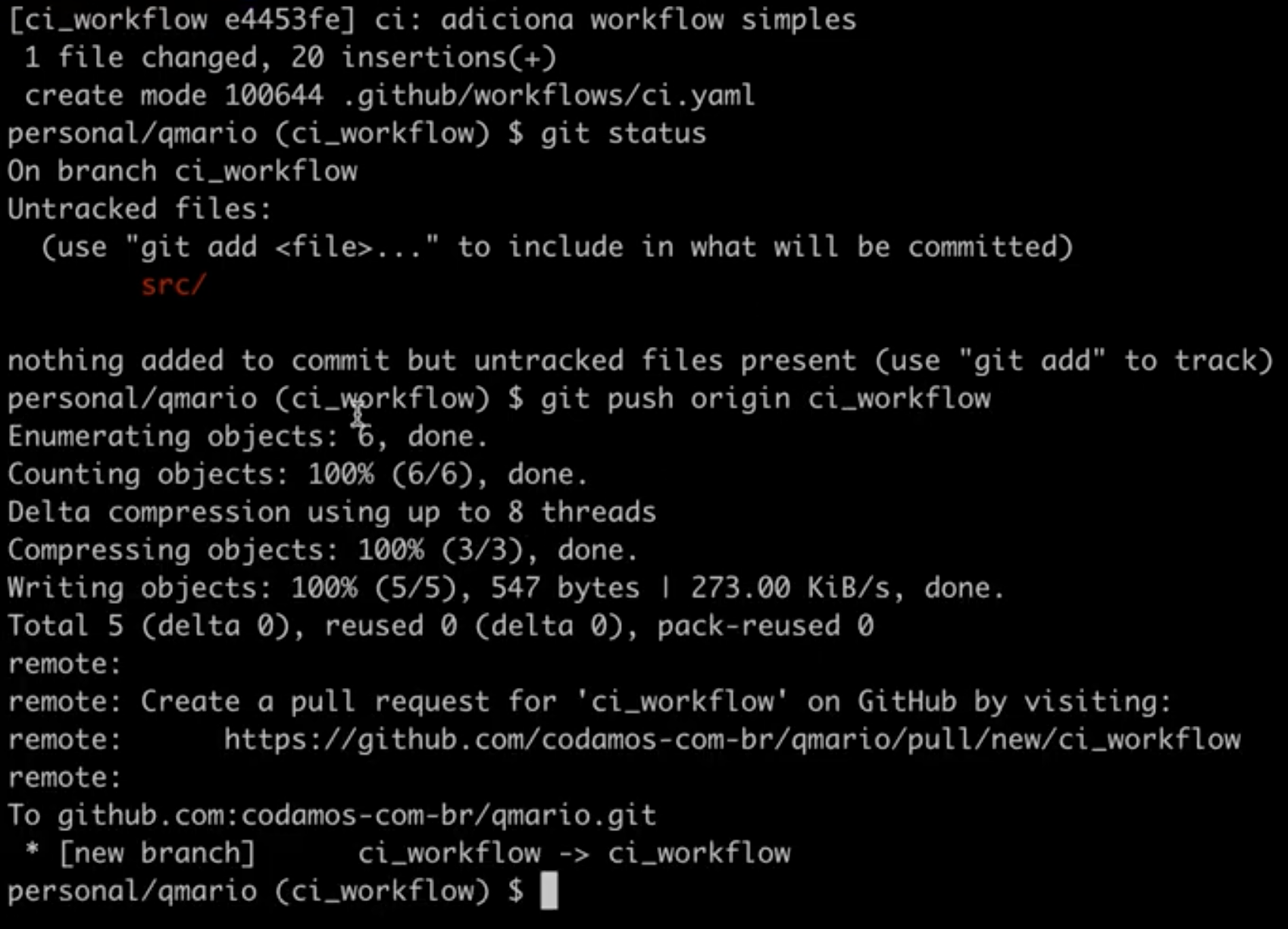
.github/workflows/ci.yaml ao branchAssim que o conteúdo for enviado ao Github, a página do seu repositório deverá oferecer de criar um Pull Request. Vamos aceitar a sugestão clicando em “Compare & pull request”:
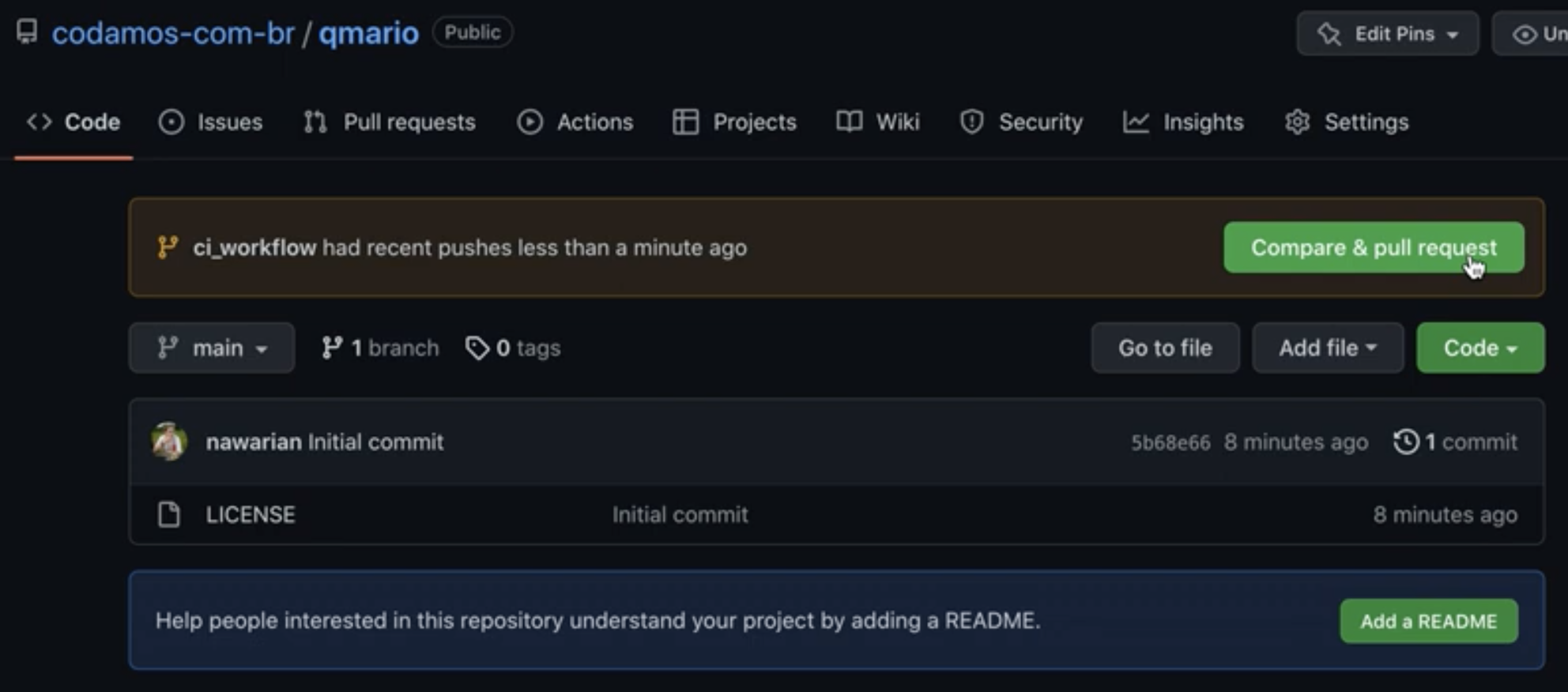
Ao confirmar a criação do Pull Request, note que o Github Actions imediatamente começa a executar a nossa pipeline:
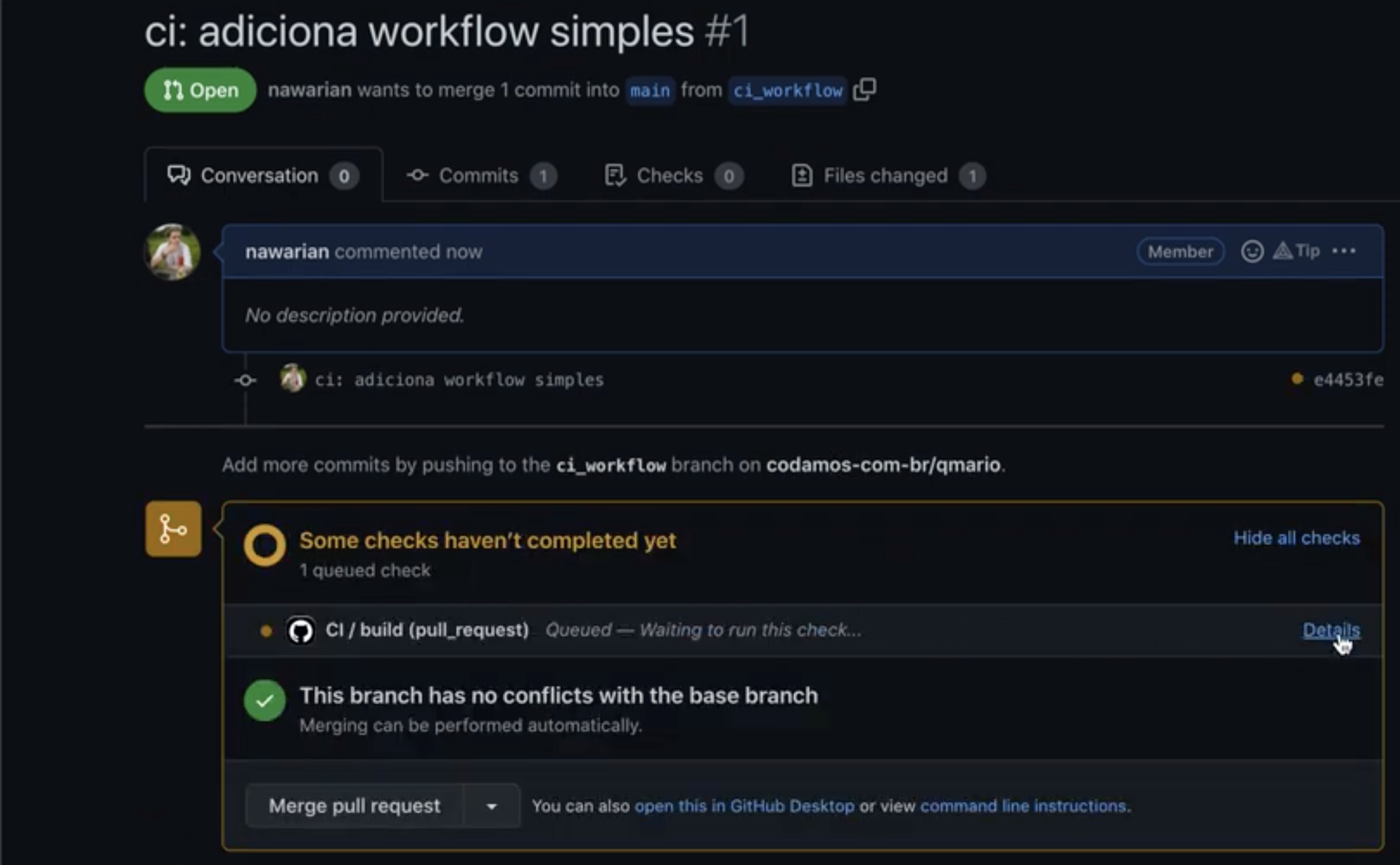
Caso os comandos desta pipeline tenham um código de saída igual a 0 (zero), a pipeline ficará verde indicando que está tudo em ordem. Caso algum código de saída seja diferente de 0, a pipeline ficará vermelha, e nos dirá qual comando teve falha.
Abaixo eu mostro detalhes de como fica a pipeline verde e expandindo o passo “Fazer build e rodar” para que vejamos a saída do nosso programa echo ‘Olá github actions’:
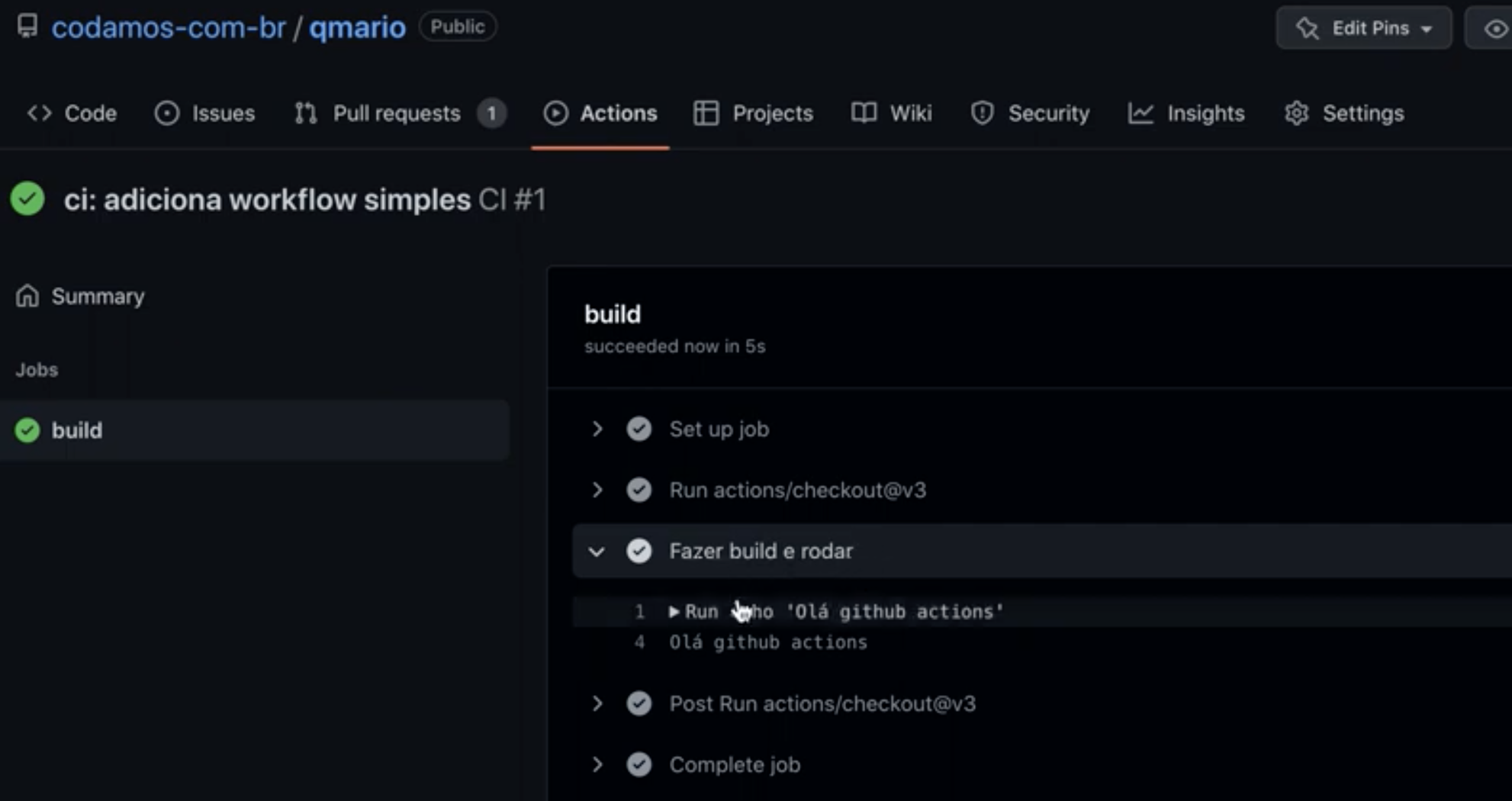
Com este workflow simples em mãos, vamos começar a botar a mão na massa e escrever um pouco de C. Deixe o Pull Request aberto, a gente ainda vai precisar dele!
Olá mundo: compilando um programa simples em C
Na linguagem C, todo programa precisa ter uma função de entrada. Normalmente esta função se chama main(). Vamos escrever um arquivo chamado src/main.c com o seguinte conteúdo:
#include <stdio.h>
int main(void)
{
printf("Olá mundo");
return 0;
}
O programa acima deverá escrever o texto “Olá mundo” na tela quando executado, e o seu código de saída (exit code) deverá ser 0 (zero). Nós podemos verificar o código de saída do último comando executado através da variável $?.
Para compilar o programa acima, utilize o seguinte comando:
$ clang src/main.c -o build/main.o -std=c99 -Wall
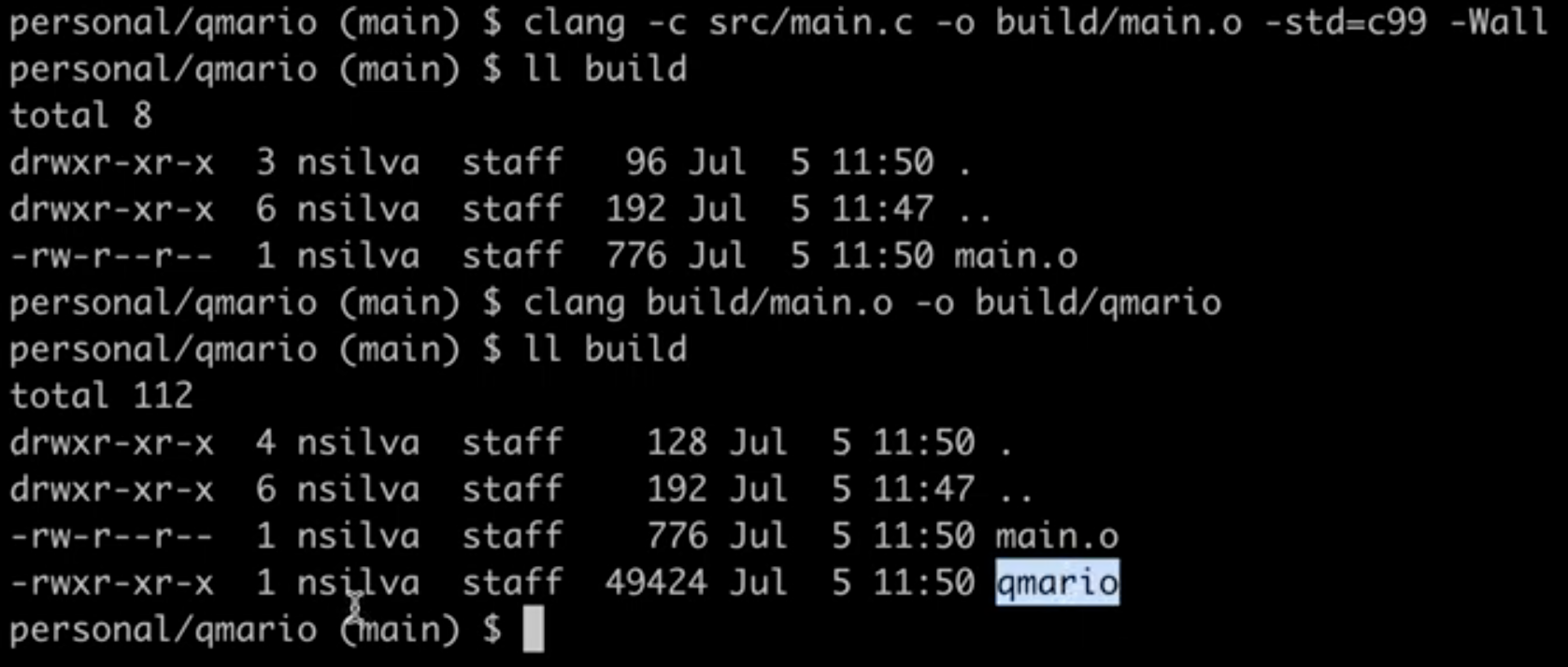
E o conjunto da obra deverá ficar mais ou menos assim:

O comando acima não apenas compilou o nosso arquivo main.c mas também executou um processo chamado Linkedição. Para facilitar a nossa vida no futuro, eu quero quebrar a compilação do nosso programa em duas partes: compilação e linkedição de objetos.
Para isto, nós primeiro precisamos compilar os arquivos .c utilizando a flag -c. Depois coletamos todos os arquivos .o e entregamos ao compilador para gerar um único executável, que aqui chamamos de “qmario”. Fica assim:
$ clang -c src/main.c -o build/main.o -std=c99 -Wall
$ clang build/main.o -o build/qmario
Criar um Makefile para o projeto
Vamos criar e editar alguns arquivos antes de mais nada. Como eu sei que no próximo post eu vou trabalhar a emulação da CPU, vamos já criar os arquivos da CPU: cpu.h (cabeçalho, onde ficam as assinaturas de função), cpu.c (implementações concretas) e cpu.test.c (testes automatizados para as funções de CPU).
Dê os seguintes conteúdos para estes arquivos:
// no arquivo cpu.h escreva o seguinte
#ifndef _cpu_h_
#define _cpu_h_
void cpu_reset(void);
#endif
// no arquivo cpu.c escreva o seguinte
#include "cpu.h"
void cpu_reset(void)
{
}
// no arquivo cpu.test.c escreva o seguinte
#include "cpu.h"
int main(void)
{
cpu_reset();
}
// no arquivo main.c escreva o seguinte
#include "cpu.h"
int main(void)
{
cpu_reset();
return 0;
}
build/ é a pasta que recebe todos os arquivos compilados e intermediários. Quando o projeto é clonado, esta pasta não deverá existir
src/ todo nosso código C ficará nesta pasta, incluindo os testes!
src/*.test.c alguns arquivos poderão receber o sufixo .test.c, que indica que são arquivos de teste. Desta forma conseguimos escrever testes e garantir maior qualidade no projeto
Portanto vamos criar o arquivo Makefile com o seguinte conteúdo:
CC=clang
CFLAGS=-std=c99 -Wall
LFLAGS=
SRCDIR=src
BUILDDIR=build
OUT=qmario
OBJS=$(BUILDDIR)/cpu.o
MAINOBJ=$(BUILDDIR)/main.o
TOBJS=$(BUILDDIR)/cpu.test.o
run: $(BUILDDIR)/$(OUT)
$(BUILDDIR)/$(OUT)
test: $(BUILDDIR) $(OBJS) $(TOBJS)
$(CC) $(OBJS) $(TOBJS) -o $(BUILDDIR)/tests $(LFLAGS)
$(BUILDDIR)/tests
# Constrói o executável principal
$(BUILDDIR)/$(OUT): $(BUILDDIR) $(OBJS) $(MAINOBJ)
$(CC) $(OBJS) $(MAINOBJ) -o $(BUILDDIR)/$(OUT) $(LFLAGS)
$(BUILDDIR):
mkdir -p $(BUILDDIR)
$(BUILDDIR)/%.o: $(SRCDIR)/%.c
$(CC) -c $< -o $@ $(CFLAGS)
.PHONY: clean
clean:
$(RM) -r $(BUILDDIR)
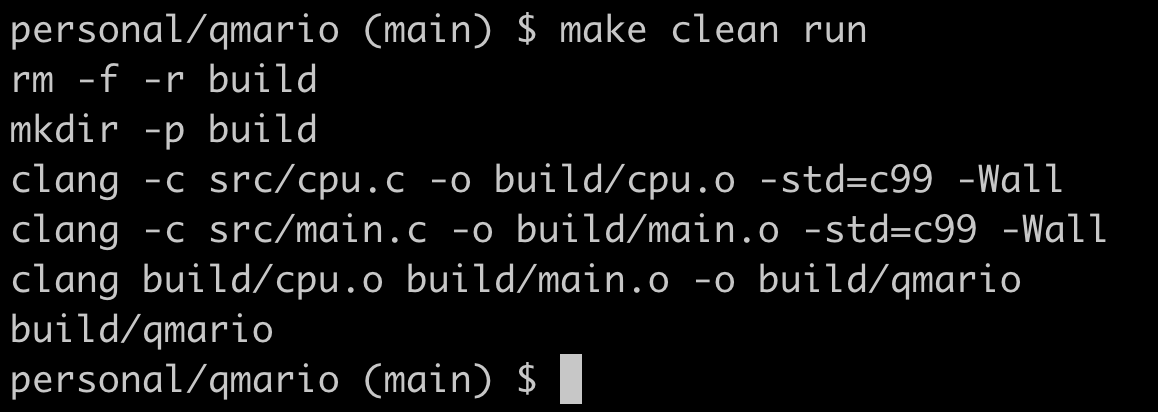
Agora que o arquivo Makefile existe, podemos executar o comando make clean run para compilar e executar o programa que definimos em main.c.
$ make clean run
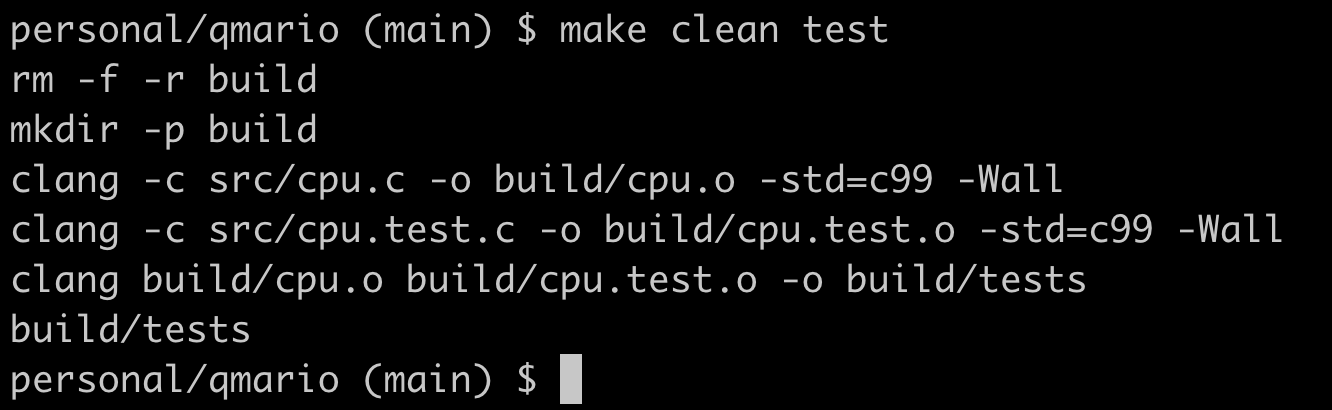
E para rodar nossos testes, definidos no arquivo cpu.test.c, podemos rodar o comando make clean test. Como a seguir:
$ make clean test
A estrutura de pastas deverá ficar mais ou menos assim:
├── LICENSE
├── Makefile
├── build
│ ├── cpu.o
│ ├── cpu.test.o
│ ├── main.o
│ ├── qmario
│ └── tests
└── src
├── cpu.c
├── cpu.h
├── cpu.test.c
└── main.c
Vamos rodar os testes como parte da integração contínua
Agora que a nosso Makefile está configurado e funcionando bonitinho, podemos alterar o arquivo .github/workflows/ci.yaml para fazermos a compilação e rodar os testes sempre que abrirmos um Pull Request no repositório que criamos.
Dê o seguinte conteúdo para o arquivo .github/workflows/ci.yaml:
name: CI
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Fazer build e rodar
run: make clean test
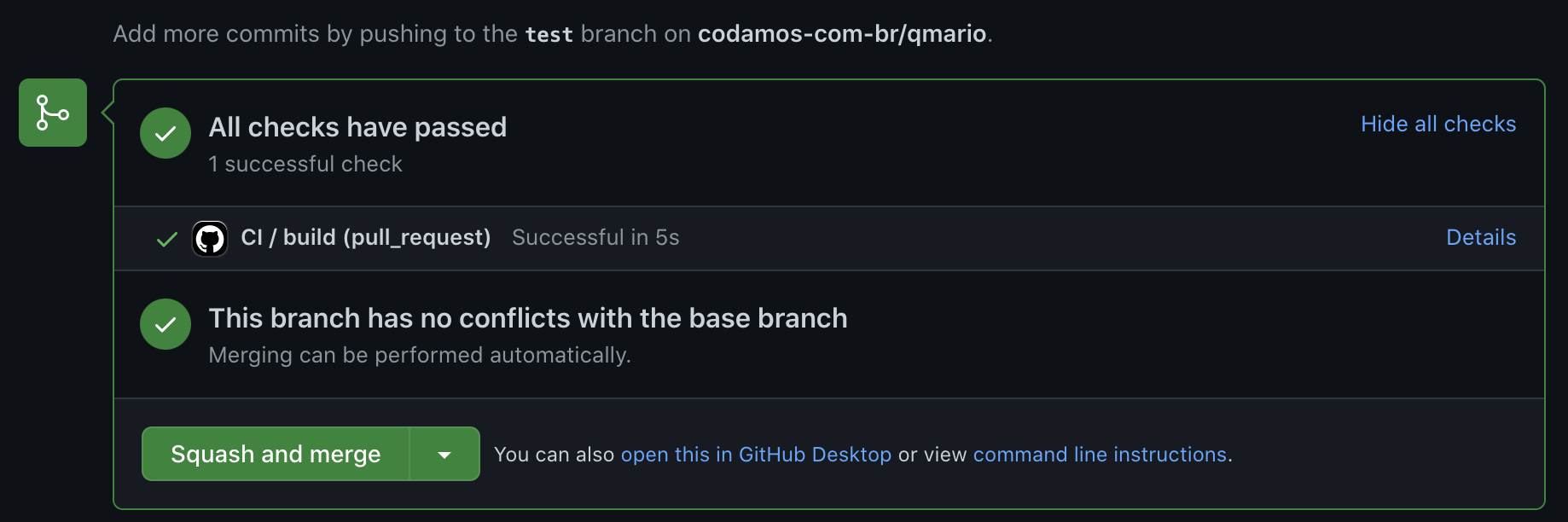
Pode enviar o código para o Github e note que o CI agora está verde, indicando que todos os passos foram executados e tudo correu bem:
Próximos passos
Já temos uma integração contínua configurada e pronta para receber nosso código. O próximo passo é começar a escrever o emulador!
O primeiro componente a ser escrito é justamente a CPU, que deverá ser escrita em conjunto com o barramento (memory BUS). No próximo artigo nós vamos começar a entender o chip 6502 utilizado pelo NES, e vamos emular algumas operações.
Não se esqueça de que o próximo artigo só sai se um número suficiente de pessoas ajudar a divulgar a série! 👇
Atenção! Para que este DevLog avance eu preciso da sua ajuda não financeira: Dê retuíte neste post e compartilhe com colegas e quem mais se interessar. Somente após 50 RTs eu vou escrever o próximo post. Esta é uma forma fácil e barata de você nos ajudar o projeto codamos.com.br a crescer ao mesmo tempo que ganha um conteúdo exclusivo e de qualidade em português.
Dá o RT, divulga e lhe vejo na próxima! 👋


Comentários